Generative pre-trained transformer (GPT) chatbots are a hot topic. They have shown their ability to help improve productivity through tasks such as programming assistance or identifying potential data sources for analysis. Unlocking the ability to harness artificial intelligence (AI) for personalized and secure applications is becoming increasingly critical for businesses looking to improve operational efficiency and drive innovation.
One such application is the development of a customized private GPT, designed to provide accurate and relevant responses based on a provided knowledge pool. The most effective method of achieving this in today’s environment is through a technique called retrieval-augmented generation, or RAG. Unlike public GPT chatbots, whose answers are generated based on generalized datasets, a private GPT chatbot is tailored to provide answers that are not only contextually appropriate but also precise and verifiable. There is a wide range of possible applications of private GPTs in the insurance industry. For example, an internal platform can be built for users to easily retrieve information from state insurance regulations, filing and reporting instructions, and other actuarial publications. A Private GPT could also be utilized to create a customer service chatbot for an insurance company to answer basic questions related to policy coverages.
This white paper explores the important concepts and the tools to build customized private GPTs.
Important concepts
What is retrieval-augmented generation (RAG)?
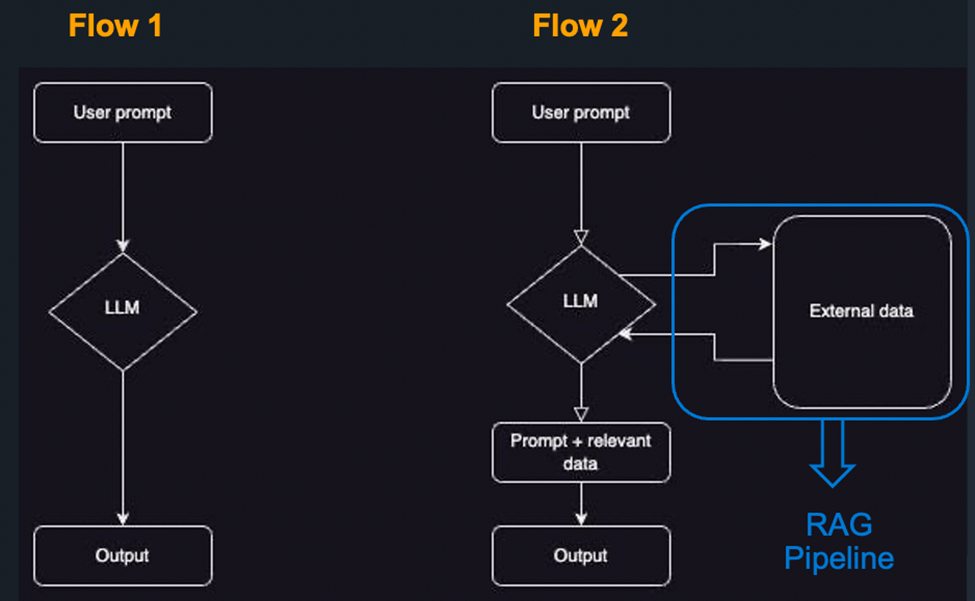
Figure 1 illustrates how RAG works to respond to a user’s prompt in the context of a private GPT. Flow 1 shows the primary steps taken when using a foundational large language model (LLM) alone:
- The user provides a prompt, which could be a question.
- The prompt is passed to the LLM.
- The LLM generates a response.
- The response is sent back to the user.
Flow 2 shows the updated procedure when RAG is involved.
- The user provides a prompt.
- The prompt is passed to the LLM.
- The LLM then searches within external data to gather information relevant to the prompt.
- The LLM combines the user prompt and the external information to generate a response.
- The response is sent back to the user, with more information than the LLM would have had on its own.
Figure 1: RAG
To further understand how RAG works, two additional concepts need to be introduced: embeddings and vector search.
What are embeddings?
Embeddings are the results of feature-learning models (usually neural networks) whose purpose is to transform natural language into vectors (lists of numbers) that capture the underlying relationships and similarities between the data points, making them more easily consumed by other models and enabling further analysis. To put simply, embeddings are vector representations of words or phrases. There are often tens or hundreds of dimensions, or entries, in a vector.
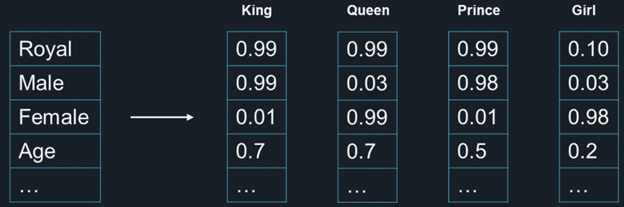
Figure 2 shows examples of embeddings, and the vectors below each of the four words (“King,” “Queen,” “Prince,” and “Girl”) are their corresponding embedded vectors. For example, if dimension 1 represents “royal,” then “King,” “Queen,” and “Prince” have relatively high values in this dimension, while “Girl” has low value in this dimension. Furthermore, “Girl” is highly similar to “Female” in the third position.
Figure 2: Embeddings
What is a vector database?
In practice, and unlike the examples above, dimensions of an embedding do not have specific, easily interpretable meanings because they are the result of sophisticated models where the embedding space captures words, their meanings, and their relationships with other words. In the context of a RAG-enhanced private GPT, a vector database is needed to store the embedded vectors generated from private data.
When a user sends a prompt to the private GPT, the RAG will search the vector database for the nearest vector or vectors and use these to generate a response. There are multiple ways to measure “closeness”, including Euclidean (straight-line) distance or a method called cosine distance. The latter generally performs better and is therefore more popular in application. Cosine distance measures the cosine of the angle between two vectors, which means it focuses on the orientation (direction) of the vectors rather than their magnitude (length). This is particularly useful when the magnitude of the vectors is not as important as their direction, which is often the case with embeddings where the relative positioning matters more than the absolute values. Cosine distance is also more stable in high-dimensional spaces.
There are also multiple approaches to search the vector database for the best match. For a given target vector (e.g., the embedded user prompt), it is possible to compute the distance to every other vector in the database (called a brute force search), but this can be slow and inefficient. More efficient methods, which most vector databases implement, involve indexing the reference data so that the target vector is only compared to the most relevant records. Indexing is an important factor that affects the performance of the vector database. While the search speed can be greatly improved using indexing, the optimal answer might be missed because of the indexing method. Nevertheless, this is usually not a major problem for RAG, because the goal is to generate reasonable answers, not optimal ones. In cases where accuracy and optimality are the highest priority, users should examine the technical details about the embedding models and algorithms used by vector databases.
The dimension of embeddings is another factor that affects the performance of the vector database for RAG1. For example, OpenAI offers two embedding models with embedding vector lengths of 1,536 and 3,072 as of the date when this paper is published.2 These embedding vectors are long because OpenAI’s models have a broad range of uses. On the other hand, if the private GPT is for a very specific use and a smaller embedding model could be trained on this specific domain, then the speed and potentially the quality of the vector search could be improved.
Vector databases can also save metadata along with each embedding to label the vectors. For example, the metadata may contain document sources to be shown as a reference in a generated answer, or a broad topic or subject label that could be used to filter vectors during the search. The ability to add data to embeddings, beyond the meanings encoded in the vectors themselves, can greatly improve the quality of RAG output when used appropriately.
Data quality
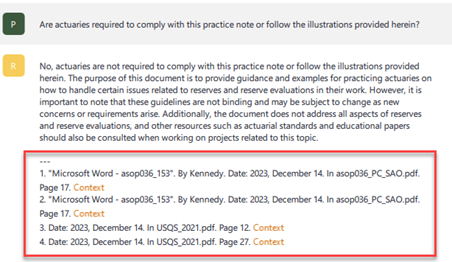
High-quality data is a requirement for producing well-performing GPTs. Developers must have a deep understanding of the data and how the GPT is able to use it most effectively. This section shows the impact that data quality can have on the performance of a private GPT. In this example, more than 10 files were provided as the knowledge pool for a RAG-enhanced private GPT. An excerpt of one of the PDF-format source files3 is shown in Figure 3.
The goal of the example is to get the answer from the red FAQ box in Figure 3 when the same or a similar question was sent to the private GPT, using Nomic GPT4All4 as the software. The source files contained complex formatting, which improves readability for humans but is challenging for machines to handle. For example, optical character recognition (OCR) was attempted by Adobe Reader and GPT 3.5 to convert this PDF to a text file, but no satisfactory result could be generated.
Figure 3: Source file – PDF format

In the first iteration, the raw PDF version of the source file was used. Figure 4 shows the answer generated. The section in the red outlined box shows the references from the knowledge pool that the RAG retrieved to answer the given question, but the true answer is not contained in the four references returned. Not surprisingly, the generated answer is not the target answer from the FAQ in Figure 3.
Figure 4: Generated answer when source file is PDF
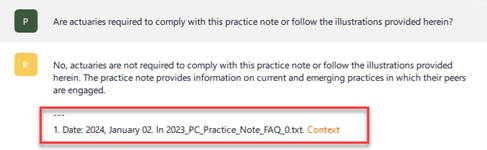
In the second iteration, the FAQ in Figure 3 was saved in a separate text file, which is provided as an additional source file along with the other files used in the first iteration. Figure 5 shows the generated answer with only this change. This time, the only reference from the knowledge pool is the new file that contains the same question. By cleaning the data in this manner, we are able to coax the model to return the desired response.
Figure 5: Generated answer when source file is TXT
The above example underscores the importance of data quality when building a knowledge pool for the private GPT. Testing by subject-matter experts that are both familiar with the source material and knowledgeable of how LLMs function is essential to ensure the source files are compatible with the selected tools and the outputs are as expected.
Risk management
Privacy and data security are major considerations when choosing platforms for private GPTs because the knowledge pool may be based on confidential information. For example, if private data was used to train a public GPT model, then users of this public GPT model may be able to obtain the private data through prompt injection. This leakage of sensitive information could lead to severe consequences, including financial loss, reputational damage, or legal implications. Therefore, it is crucial to implement robust data governance policies to ensure that private data remains secure and is not inadvertently exposed. When third-party data is involved, extra care needs to be taken to ensure permissions and licenses are honored. This includes thoroughly reviewing the terms of service and data usage agreements associated with third-party data sources.
Developers of private GPTs also need to be aware of biases present within the LLM selected. For example, gender bias is a common issue of LLMs, where doctors are usually connected with males and nurses are connected with females. Such biases can perpetuate stereotypes and result in unfair or inaccurate outcomes. Developers need to consider the impact of bias on the results and how to limit or mitigate these risks. Involving a diverse team of developers and stakeholders in the model development process can provide diverse perspectives and help in identifying and mitigating biases.
Misuse and overreliance can also be a big issue. Users must keep in mind that the answers generated by private GPTs, and LLMs in general, can be hallucinations (nonsensical or inaccurate output that appears correct). They are not always right, and users need to be responsible for deciding whether a generated answer is proper and correct. To help users make the right decisions, the references used from the knowledge pool can be returned together with the generated answer. This transparency allows users to verify the information and make informed decisions. Training and educating users on the limitations and appropriate use of GPTs can also help in reducing misuse and overreliance. Implementing feedback mechanisms where users can report inaccuracies or issues with the generated content can further improve the reliability and trustworthiness of the system.
Considerations when choosing tools to build private GPTs
When choosing the tool to build private GPTs, there are some important considerations:
- Local or cloud: Local tools place a safeguard on the private data, while cloud-based tools may require additional approvals before providing sensitive data to the private GPT.
- Speed of generating responses: How long can the users wait for each generated answer before closing the tool and walking away?
- Single user or groups of users: If there is a group of users, can the tool ensure consistency? How scalable is the tool?
- Flexibility: Does the tool allow modifying parameters that affect the performance of RAG, like chunking, parsing, indexing, and retrieval algorithms? Can the user interface of the tool be customized?
- Resources available to develop the private GPT: How much experience do the developers have with LLMs, RAG, and writing computer code? If enough resources are available, a totally customized tool can be built from scratch.
Figure 6 shows some popular tools that support developing private GPTs and a comparison of their features and limitations.
Figure 6: Tools available
| Name of the Tool | Features | Limitations |
|---|---|---|
| OpenAI GPT Builder | - No coding needed - Tools available to monitor the private GPT, including the usage and the cost of running the private GPT - Newly released OpenAI LLM can be easily utilized |
- Privacy of data - As of November 2024, GPT Builder can support at most 20 files with a limit of 512 MB per file5 |
| Microsoft CoPilot Studio | - No coding needed, but allows adding features like collecting feedback for every response6 - Accepts multiple types of data sources, including public websites, internal SharePoint file shares, and individually uploaded files - Easy to publish the private GPT to other Microsoft platforms, including SharePoint and Teams - Readily available analytics to monitor performance, like abandon rate (ratio of users who close the webpage before getting a response) and billing information (cost incurred by running the current private GPT) |
- Limited flexibility: no control over RAG and LLM parameters |
| Nomic GPT4All | - Desktop version (local) available and no coding needed - Multiple LLMs available - Relatively flexible: some RAG and LLM parameters can be modified - GPT4All automatically creates the vector database when knowledge pool is provided and it refreshes in real-time when knowledge pool changes |
- Hard to ensure consistency between group users because RAG and LLM parameters are specified locally - Slow (depends on hardware of host machine) - Hard to scale because it uses host machine hardware resources |
| Custom-built example: - Primary programming language: Python - Hosting: Internally - LLM: OpenAI models - Vector database: Typesense |
- Complete flexibility | - High requirement of knowledge about LLMs, RAG, and programming |
This list is no doubt incomplete, and this rapidly evolving technology will spur development, disruption, and innovation across the insurance industry and beyond.
Closing
Private GPTs can help users find answers based on private data. The successful development of customized private GPTs hinges on a thorough understanding of RAG, embeddings, and vector databases, maintaining high data quality, and a commitment to maintaining and updating the model. By carefully considering these elements and selecting appropriate tools, developers can create powerful, reliable, and secure language models tailored to their unique requirements. As the field of AI continues to evolve, ongoing research and innovation will undoubtedly yield new techniques and tools, further enhancing our ability to build sophisticated private GPTs. Staying informed about these advancements will be essential for anyone looking to leverage the full potential of generative AI in their respective domains.
1 Tang, Y., & Yang, Y. (2024). Do we need domain-specific embedding models? An empirical investigation. Retrieved December 3, 2024, from https://arxiv.org/abs/2409.18511v3.
2 OpenAI Platform. Vector Embeddings. Retrieved November 8, 2024, from https://platform.openai.com/docs/guides/embeddings/what-are-embeddings.
3 American Academy of Actuaries. Retrieved November 8, 2024, from https://www.actuary.org/sites/default/files/2023-12/casualty-practice-note-saopclossreserves.pdf.
4 GPT4All. Run Large Language Models Locally. Retrieved November 8, 2024, from https://www.nomic.ai/gpt4all.
5 OpenAI. File Uploads FAQ. Retrieved November 8, 2024, from https://help.openai.com/en/articles/8555545-file-uploads-faq.
6 Microsoft Copilot Studio (July 2, 2024). Add feedback for every response. Retrieved November 8, 2024, from https://learn.microsoft.com/en-us/microsoft-copilot-studio/guidance/adaptive-card-add-feedback-for-every-response.